selenium(Python)でstyleが"display: none;"となっている要素を取得する
他の人も既に同様の記事を書いているのですが、メモ代わりにブログに残します。
使える場面
例えば以下のような<li>タグがあった場合、
<li style="display: none;">
<a href="...">
<div class="title">fuga</div>
</a>
<div class="description">xxxxxxxxxxx</div>
</li>
<li style="display: none;">
<a href="...">
<div class="title">hoge</div>
</a>
<div class="description">xxxxxxxxxxx</div>
</li>
...
こういうの、ページネーションとセットでよく出てくる気がします。
次ページの番号をクリックすると、別リンクに飛ばすよくある仕様でなく。
指定した番号に対応する<li>をnoneからblockなどに切り替えると同時に、それ以外の<li>タグをnoneに切り替え非表示とすることで、ユーザーに他ページに飛んだように見せることがよくある気がします。
こういうサイト。例えばBeautifulSoupでスクレイピングしようとしてもうまくいかないので、seleniumを使ってjsをいじりながらやっていくのが早いかと思います。
コード
seleniumでjsのコードを動かす場合、execute_scriptメソッドが非常によく使われるかと思います。例えば要素をクリックしたり、スクショしたり、、、etc.
そんなexecute_scriptですが、styleの書き換えも簡単に行うことが可能です。
driver.execute_script("arguments[0].style.display='block';",{要素})
結果の確認
確認のため状況HTMLをローカルに保存してseleniumでスクレイピングしてみます。まず以下のコードでローカルに保存したHTMLファイルを開いてみます。
url = 'file://{htmlファイルの絶対パス}'
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
結果

非表示であることが確認できます。 次に以下の行を追記してコードを再実行してみます。
url = 'file://{htmlファイルの絶対パス}'
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
elems = elems.find_elements_by_tag_name('li')
for elem in elems:
driver.execute_script("arguments[0].style.display='block';", elem)
結果

CSSが書き換えられ<li>タグの中身が表示されているのが分かります。これで.textでテキストを取得したりすることも可能になります。
YahooニュースのRSS一覧から好きなニュースをチョイスして新着情報を通知してくれるようにした話


pandasでexcelを開くときは「xlrd」より「openpyxl」の方が安定してるかもしれない話
はじめに
pandasを初めて使って早2年強。この度業務で初めてexcelファイルを取り扱う必要が出てきました。
テキストファイル安定のこのご時世、エクセルみたいなバイナリーファイルという時点で不安はあったのですが、案の定読み込みの時点で少し面倒だったので一応解決法などをメモしておきます。
尚、pandasのバージョンは1.2.1です。
解決法
まず普通にread_excelで読み込もうとすると以下のエラーが
importerror: missing optional dependency 'xlrd'. install xlrd >= 1.0.0 for excel support use pip or conda to install xlrd.
なんでもxlrdというライブラリが別途必要とのこと。そこで現時点で最新だったバージョン2.0.1をインストールして再度試してみることに
your version of xlrd is 2.0.1. in xlrd >= 2.0, only the xls format is supported. install openpyxl instead.
またまたエラーです。どうやら2.0以上のxlrdだとエクセルの拡張子がxlsのものしか読み込めず、比較的新しいxlsxのものに関してはエラーが発生してしまうようです。時代に逆行してますね。
xlrdのバージョンを1.2.0に下げてみました。
attributeerror: 'elementtree' object has no attribute 'getiterator'
は??
本日3度目のエラー。エクセルファイル恐るべしです。
どうやら調べてみると結局xlrdよりもopenpyxlの方がよさげ、バージョン3.0.6をインストールし下記のようにreac_excelの引数に以下を加えたところ、ようやくファイル読み込みができました。
df = pd.read_excel('data.xlsx', engine='openpyxl')
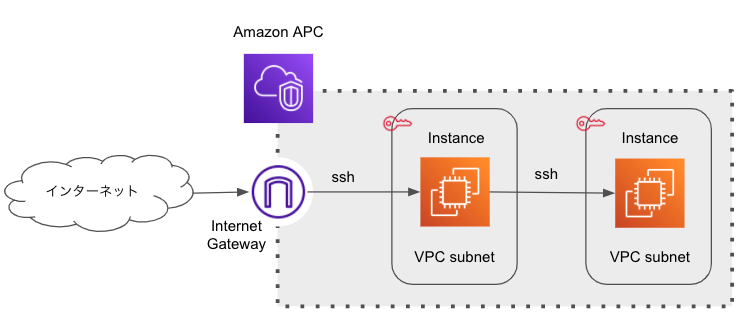
【AWS】踏み台サーバを利用した多段sshを構築しVScodeで接続するまで
多段sshでサーバーを構築することになったので作業がてらメモ。尚、プライベートサブネット内のEC2からの戻りトラフィックを有効にしたい場合、下記構成にプラスして、NATゲートウェイをパブリックサブネット内におき、プライベートサブネットへのルーティングを設定しないと行けないので追加作業が必要です。(このブログでは書いていませんが)
イメージ図
ネットワークの設定
VPCの作成

後ほどDNSからホスト名を割り当てられる様、DNSホスト名を有効化する。

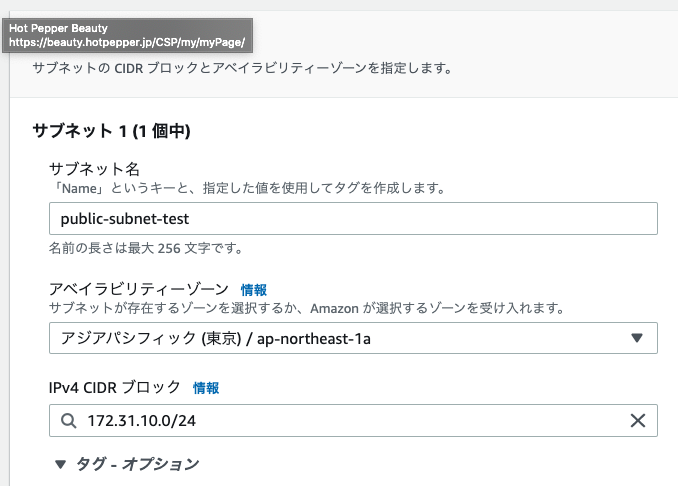
サブネットの作成
- 先ほどのVPC空間に割り当てられたアドレス範囲内で、public subnetとprivate subnetの2つのサブネットを作成します。
- 下記キャプチャはpublic subnetの例、先ほど指定したVPCのアドレス範囲(172.31.0.0 ~ 172.31.255.255)の内、172.31.10.0 ~ 172.31.10.255をpublic subnetに分割している。
Internet Gatewayの作成
Route Tableの作成
private route table(デフォルトで作成されたルートテーブル)は分かりやすいように名前をつけておく。

public用の作成したルートテーブルには、先ほど作成したインターネットゲートウェイへのルートを追加する。

サブネットの関連付けで[編集]を押下し、先ほど作成したpublic subnetを追加する。

セキュリティグループの編集
- デフォルトで作成されたセキュリティグループは「同一セキュリティグループ内の制限なしアクセス」が定義されているだけなので、インバウンドルールを編集する。

尚、これとは別にprivateサーバー用のセキュリティグループも用意する。
EC2作成
踏み台サーバー作成
(今回OSはubuntu 20.04.LTSで作成)
先ほど作成したVPC領域と、public subnetを指定し、パブリックIPアドレスの自動割り当てを有効化する。

このインスタンスにはプライベートIPアドレスも指定する。先ほど指定したアドレスの範囲から指定(指定しなければ自動的に割り当てもされる)
尚、セキュリティグループの設定は先ほど作成した既存のもの(public用)を指定する。
privateサーバーの作成
先ほどのpublicサーバーと殆ど同じだが、自動割り当てパブリックIPを無効化することを忘れずに(仮にIPアドレスが割り当てられても外部からは繋がらない)。尚、割り当てるサブネットやセキュリティグループもprivate用にする。間違えてpublic用にしないように注意
踏み台サーバーからプライベートサーバーにsshアクセス
まず、以下のコマンドで踏み台サーバーへアクセスできることを確認
ssh -i {秘密鍵} {ユーザー名}@{パブリックIPv4アドレス}

次に以下のコマンドでプライベートサーバーへ外部インターネットから一気にログインできることを確認
ssh -o ProxyCommand='ssh -i {秘密鍵} {ユーザー名}@{踏み台サーバーパブリックIPv4アドレス} -W {プライベートサーバーのローカルIPアドレス}:22' -i {秘密鍵} {ユーザー名}@{プライベートサーバーのローカルIPアドレス}

同じubuntuマシンなので分かりづらいですが、先ほどの踏み台サーバーとは異なるローカルIPアドレスである事が分かります。
次回以降のログインを楽にするために~/.ssh/configに以下のように追記します。
Host {publicのホスト名}
HostName {踏み台サーバーパブリックIPv4アドレス}
Port 22
User {ユーザー名}
IdentityFile {秘密鍵}
ForwardAgent yes
Host {privateのホスト名}
HostName {プライベートサーバーのローカルIPアドレス}
Port 22
User {ユーザー名}
IdentityFile {秘密鍵}
ProxyCommand ssh -W %h:%p {publicのホスト名}
そうすれば次回以降ssh {privateのホスト名}で一発ログインできます。楽だし、踏み台サーバーに秘密鍵を置いたりする必要もなく安心です。
VSCode で接続
以前の記事のVSCodeで編集を参照
ImageOnlyTransformクラスを継承して、RandomShadowのdata augmentationを実装
CutoutとRandom Erasing
最早定番となったdata augmentationの手法であるCutout/Random Erasing、入力画像をランダムなマスクで欠落させることで、より強い正則化の効果を作り出すことを狙いとしています。
Cutout [arXiv]

Random Erasing [arXiv]

albumentation
data augmentation時によく使われるalbumentationsですが、基底クラスを継承する事で自作のdata augmentationクラスを作成することができます。 Albumentationは次の2つの基底となるクラスが存在します。
- ImageOnlyTransform・・・画像のみに処理を適用する
- DualTransform・・・画像+物体検出(+その他)に処理を適用する
実際に作成する際はinputする画像だけに処理すれば良いのか、それとも教師ラベルとなるマスク自体にも処理をすべきなのかで上記2つのどちらを継承するかが変わってきます。
RandomShadow
先ほどまでのCutoutなどとは異なり、完全に情報を欠落させるのではなく、輝度を落としたい場面がでてきたので新しく自作クラスを作成しました。
ImageOnlyTransformを継承したRandomShadowの実装
実際に使用してみたイメージです。
import cv2 import matplotlib.pyplot as plt random.seed(1) img_origin = cv2.imread('baseball.png') img_origin = cv2.cvtColor(img_origin, cv2.COLOR_BGR2RGB) img = img_origin.copy() img_shadow = RandomShadow(p=1.0)(image=img)['image'] fig, axes = plt.subplots(1, 2, figsize=(12, 6)) axes[0].imshow(img_origin) axes[1].imshow(img_shadow) plt.show()

Linuxのrenameコマンドについて
経緯
手元にある大量のjpgファイル。頭文字に一括で文字を付けたい時に今までは以下のコマンドで行っていました。
# rename "s/[変更前]/[変更後]" [ File-Path ] # 拡張子に".jpg"をもつ全てのファイルに対して先頭に"hoge-"を追加 $ rename "s/^/hoge-/" *.jpg
ただ今まで問題なかったこのコマンド。他の環境で同じようにやろうとしたところ、使えないという事態に陥ってしまいました。
解決法
実は上記のコマンドは、Ubuntu環境下でのrenameでした。今回はCentOSを使用していたので、上記のコマンドが使えなかったようです。下記のコマンドで無事処理することができました。
# rename [変更前] [変更後] [ File-Path ] $ rename "" hoge- *.jpg
AtCoder 東京海上日動 プログラミングコンテスト2020
AB2完の緑パフォでした。そして今回のコンテストでようやくレート緑になることができました!

個人的にレート緑は最初の目標として掲げていたので、ようやくですが入緑できてほっとしています。これからも少しずつ伸ばしていきたい。
A - Nickname
概要
- 省略
コード
S = input() print(S[:3])
B - Tag
概要
- 二次元軸での鬼ごっこ問題。鬼役の座標と速度。逃げる役の座標と速度が与えれるので、制限時間以内に追いつけるかどうかを判定。
制約
省略
考察
省略
コード
A, V = map(int, input().split()) B, W = map(int, input().split()) T = int(input()) diff = abs(A-B) if (V-W)*T >= diff: print('YES') else: print('NO')
C - Lamps
概要
- 省略
制約
考察
今回解けなかった問題。解説で学んだいもす法を振り返りながら実装して行こうと思います。
いもす法の考え

スライドにしてみましたが、これが一番分かりやすいと思います。左図はのように一定の区間をドンドン足し合わせていく操作については、右図のようにその始点と終点+1のポイントに着目することで、大幅に計算量を減らせます。(始点と終点の間全てに+1をしてしまっては計算量が膨大になってしまうことはイメージできると思います。)よってこの方法を使うと、スライドの操作自体は見ての通り、になるので、これを
回だけ繰り返すとすると、
で問題を解くことが可能です。
ただここで問題が一つあり、最悪ケースの場合(
)で
だとAtCoderでは通りません。ただこれも解説で触れていたのですが、今回の問題設定の場合、
の操作で収束してしまうことが分かるので、
はが
回以上の場合、問答無用で答えは
[N] * Nの配列になってしまいます。
コード
import numpy as np from numba import jit N, K = map(int, input().split()) A = np.array(list(map(int, input().split())), dtype=np.int64) # 高速化 @jit def imo(a, n): imos = np.zeros(n+1, dtype=np.int64) for i in range(n): imos[max(0, i-a[i])] += 1 imos[min(n, i+a[i])+1] -= 1 # 累積和はnumpyの方が高速 immo = np.zeros(n+1, dtype=np.int64) immo = np.cumsum(imos) return immo[:n] for _ in range(min(K, 41)): A = imo(A, N) print(*A)